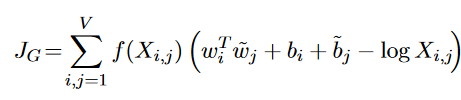Vor einiger Zeit war ich auf einer Veranstaltung zum Thema Super-Diversity (Superdiversität) und Migration.
Via Google lande ich beim Thema Superdiversität im Online-Universum der Max-Planck-Gesellschaft:
«Der Kulturanthropologe Steven Vertovec beschreibt diese Komplexitätssteigerung sich überschneidender Formen von Unterschiedlichkeit als Superdiversität (super-diversity). Superdiversität in Vertovecs Sinne verweist auf eine komplexe mehrdimensionale Diversifizierung bereits existierender Formen sozialer und kultureller Vielfalt.» (‚Diversität und Gesellschaft‘, Fußnoten entfernt (mpg.de))
Sehr verkürzt ist Superdiversität die Diversifikation der Diversität:
«It has also been called the «diversification of diversity» (en.wikipedia.org)
Eine kulturelle Praktik, in der ‚Formen sozialer und kultureller Vielfalt‘, aber auch Alter- und Gender-Unterschiede produziert und reproduziert werden ist: unsere Sprache.
Superdiversität und inklusive Sprache
Welche Auswirkungen hat die Diversifikation der Diversität für das Projekt einer inklusiven Sprache?
Inklusive Sprache, so wie ich sie in meinem eBook skizziere, ist diversitäts- und auch super-diversitäts-sensibel 🙂
Das Konzept der Superdiversität unterstreicht jedoch die Wichtigkeit zweier Punkte für eine inklusive Sprache:
1. Kein generisches Maskulinum
Denn das generische Maskulinum ist nicht diversitäts-sensibel, weil es die Anforderung an eine sprachliche Gleichbehandlung nicht erfüllt. Frauen mitzumeinen ist nicht diversitäts-sensibel, sondern exkludierend, benachteiligend.
Wenn das generische Maskulinum schon bei dem Anspruch an sprachlicher Gleichbehandlung von zwei geschlechtlichen Identitäten versagt, dann kapituliert es komplett bei super-diversen Anforderungen; wie z.B. die sprachliche Inklusion von super-diversen sexuellen Identitäten.
Deshalb sind geschlechtsneutrale Formulierungen, immer wenn möglich, die Super-Lösung!
2. Keine sprachliche Markierung von personenbezogenen Merkmalen
Für eine inklusive Sprache, in der sich auch super-diverse Menschen wohlfühlen, gilt das gleiche, wie für eine inklusive Sprache und eine ’normale‘ Diversität, nämlich:
Ich markiere keine Differenz, keine (Super-) Diversität, kein Anderssein durch Sprache.
Es sei denn: ich habe einen ’sachlichen Grund‘ (siehe das AGG § 20) oder es besteht ein ‚begründetes öffentliches Interesse‘ (siehe den Deutscher Pressekodex Ziffer 12).
Die Frage ist also zuerst: wieso will ich überhaupt (Super-) Diversität sprachlich abbilden?
Beispiel: jung=technik-affin und älter=nicht technik-affin?
Kurz-Fazit
Superdiversität ist keine Herausforderung für eine inklusive Sprache. Ganz im Gegenteil; ich denke, nur mit und in einer inklusiven Sprache ist Superdiversität möglich.
Das Konzept der Superdiversität verweist jedoch stark auf:
«…den relativen Bedeutungsverlust von Kollektivität [z.B. Nationalität, Geschlecht, Alter, Ethnizität] als Beschreibungskategorie in komplexen Gesellschaften.» (‚Diversität und Gesellschaft‘ (mpg.de) [ich])